
Using The Python Csv Module
Jay
Tue Oct 08 2024 10:56:13 PM PDT
Do you ever just need to work with data from Excel in Python, or open up a CSV (comma-separated values) file and parse through its contents? You may not know this, but Python already comes prepackaged with a “csv” module. So there is no need to download an external module like “pandas” to work with CSV files.
Let’s first dive into what a CSV file is:
For this example I’m going to use a file called, “biostats.csv” — which can be downloaded from here.
When you open up the CSV file it will look like this in MS Excel:
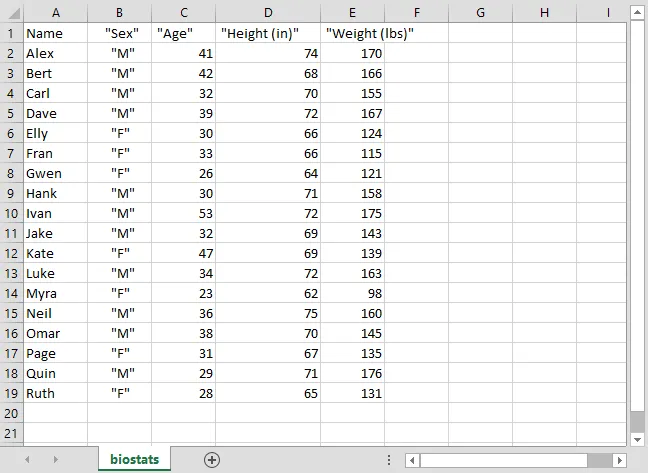 biostats.csv in Excel
biostats.csv in Excel
However, if you were to open it up in its raw format in Notepad, you would see how simple the inner structure of a CSV file is:
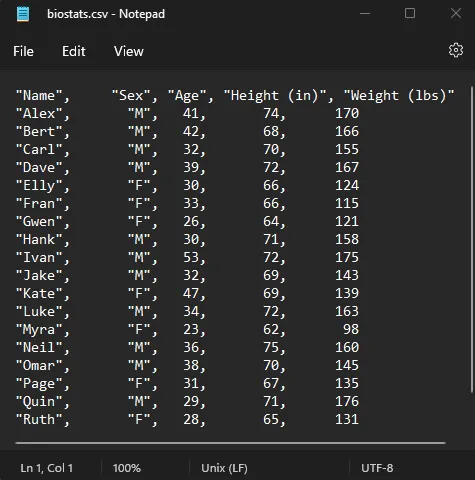 biostats.csv in Notepad
biostats.csv in Notepad
We can see that the file is — as the name CSV suggests — values separated by commas and terminated by a new line. Knowing this structure will allow us to pick apart the file with relative ease.
Now, let’s jump into the code!
When we run the above code we should see the following output:
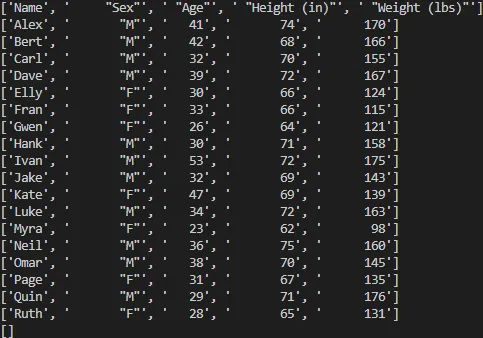 Python output of biostats.csv
Python output of biostats.csv
This is useful, and now we can start doing stuff with this data in Python. However, we can make working with this data a little easier on ourselves. Because we now know how the CSV file is structured, we can use Python to simplify our ways of working with this data. For starters we can store the column numbers in constants to easily reference data when we have read it into Python.
It’s reasonable to write the constants as standalone; however, I find it incredibly useful to enumerate my constants in a class object, especially if using an IDE that auto completes.
For example:
Alright, we have a lot going on here:
We have added a class to represent information about the CSV file. We know this file has headers, so we set a Boolean constant “HAS_HEADERS” to “True”, we enumerated the column locations of headers into meaningful constant names.
Then when we’re reading the file we use the Python native “next” function to store the headers into a separate list variable for potential future use.
After storing the headers, we told the iterator object “reader” to start at the next row. Knowing this we begin to parse the data, and we want to start doing something meaningful with it. In this instance, we’re just going to grab the name of the participant and their associated age. However, we only want to see people in their 20’s.
At line 26 in the code above, there’s a couple important conditions to mention here. The “if line” condition is checking to see if the line has data in it, if it is empty, we won’t do anything with that line. The next condition is “len(line) > BioStats.WEIGHT_COL”. Because we know that “BioStats.WEIGHT_COL” is the last column, it’s safe to use this as a reference to check if the line list value’s length is long enough to check if it contains content. This could happen in CSV file when a row is not completely filled in with data, and it’s good practice to check for input errors like this to have a safe reading algorithm.
Finally once we have completed those conditions, we check to make sure the person’s age is in their 20’s, then format the information into something meaningful to print out.
Output:
Gwen is 26 years old.
Myra is 23 years old.
Quin is 29 years old.
Ruth is 28 years old.
I love working with computers, especially in the context of data and spreadsheets. It’s my hope that articles like this excites others in how Python can be used in real world practical ways.
Cheers,
Jay